
I'm delighted to announce the liberate of Screaming Frog SEO Spider 9.0, codenamed internally as '8-year Monkey'.
Our team were busy in building working on exciting new facets. In our remaining replace, we released a brand new consumer interface, in this unlock we've a brand new and intensely powerful hybrid storage engine. here's what's new.
1) Configurable Database Storage (Scale)The web optimization Spider has historically used RAM to save records, which has enabled it to have some remarkable merits; helping to make it lightning quickly, super flexible, and offering precise-time statistics and reporting, filtering, sorting and search, throughout crawls.
however, storing statistics in reminiscence also has downsides, chiefly crawling at scale. here is why version 9.0 now makes it possible for users to decide to save to disk in a database, which permits the search engine optimisation Spider to crawl at truly unprecedented scale for any desktop utility whereas preserving the identical, general real-time reporting and usability.
The default crawl limit is now set at 5 million URLs in the SEO Spider, but it isn't a hard restrict, the search engine marketing Spider is in a position to crawling vastly greater (with the appropriate hardware). listed below are 10 million URLs crawled, of 26 million (with 15 million sat within the queue) for instance.
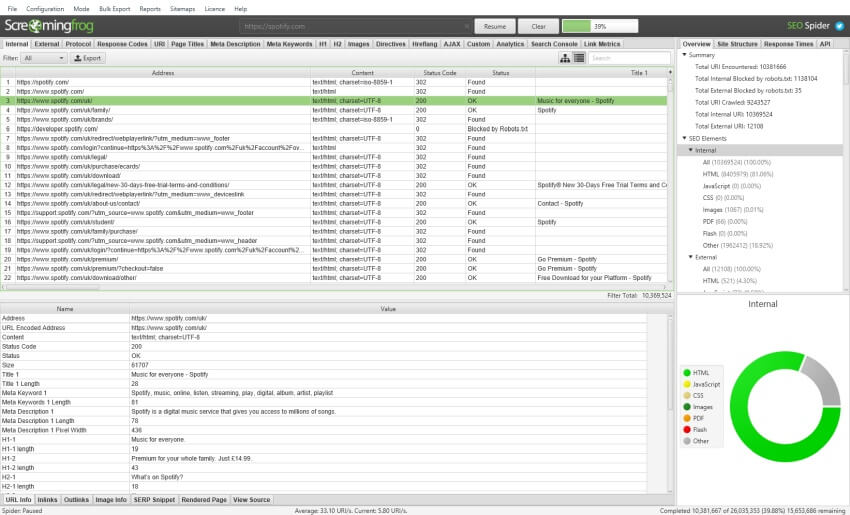
we now have a hate for pagination, so we made sure the search engine optimisation Spider is effective sufficient to permit users to view records seamlessly nonetheless. for example, that you can scroll via 8 million web page titles, as if it turned into 800.
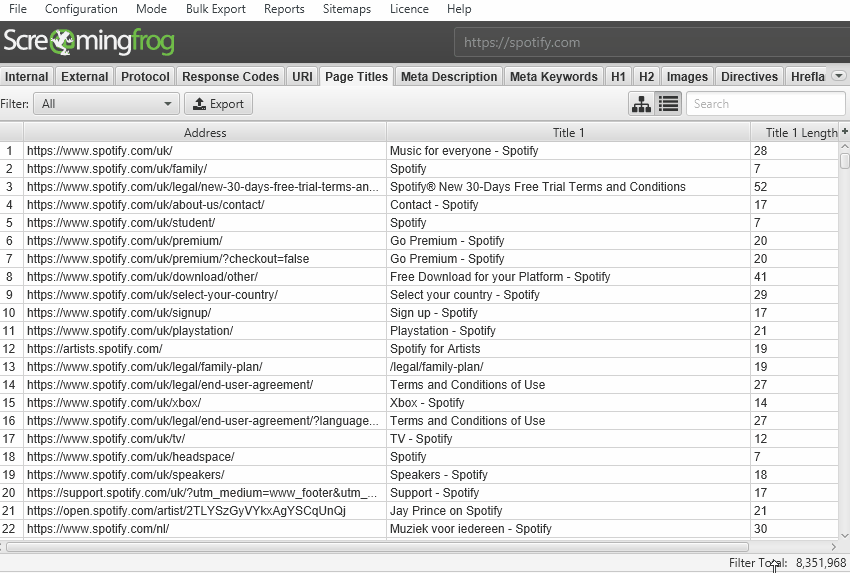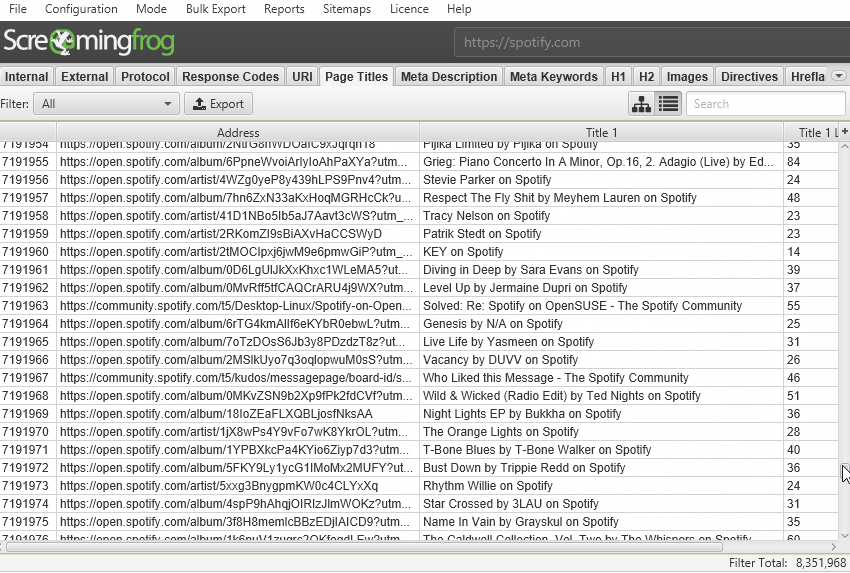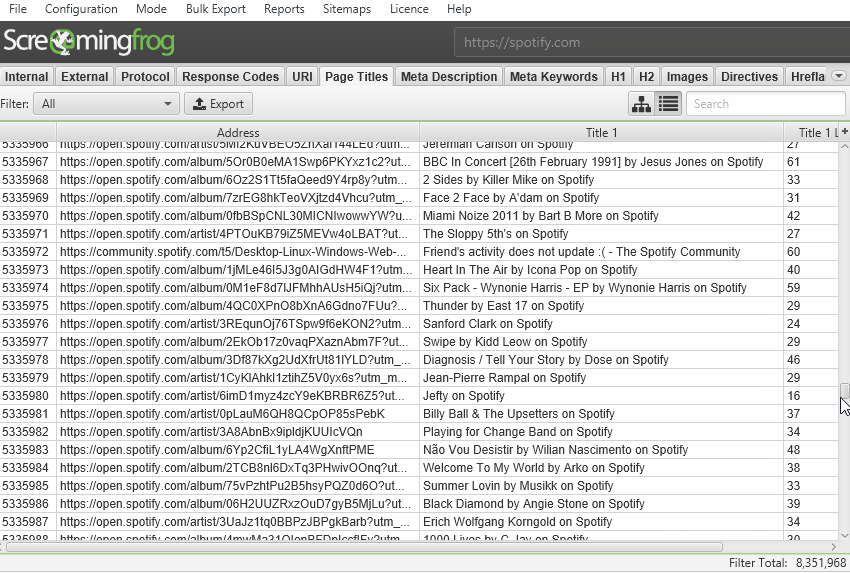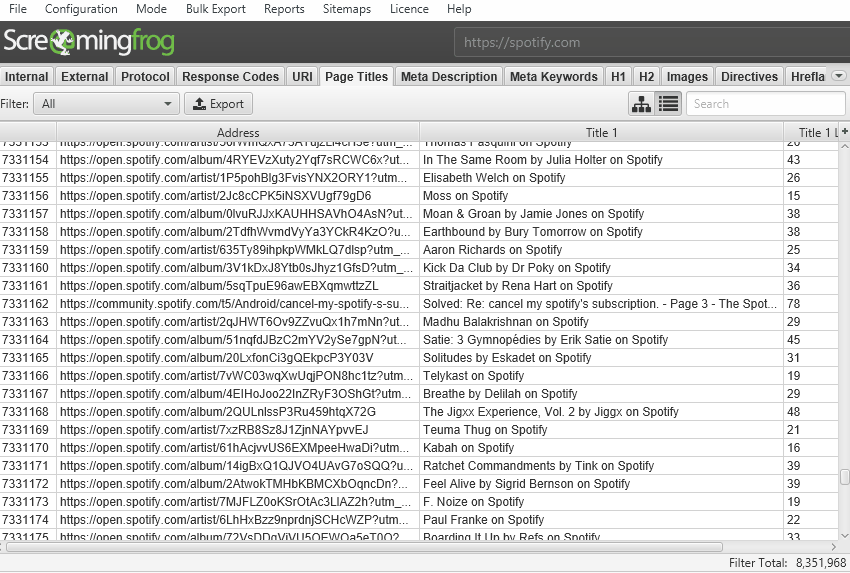
The reporting and filters are all immediate as neatly, however sorting and looking out at big scale will take the time.
It's important to be aware that crawling is still a reminiscence intensive system in spite of how information is kept. If statistics isn't kept in RAM, then loads of disk area might be required, with satisfactory RAM and ideally SSDs. So fairly potent machines are nevertheless required, otherwise crawl speeds will be slower in comparison to RAM, as the bottleneck becomes the writing speed to disk. SSDs permit the SEO Spider to crawl at close to RAM speed and read the records straight, even at big scale.
by means of default, the website positioning Spider will save records in RAM ('reminiscence storage mode'), but users can choose to retailer to disk in its place with the aid of choosing 'database storage mode', within the interface (by way of 'Configuration > system > Storage), based mostly upon their computer requirements and crawl necessities.
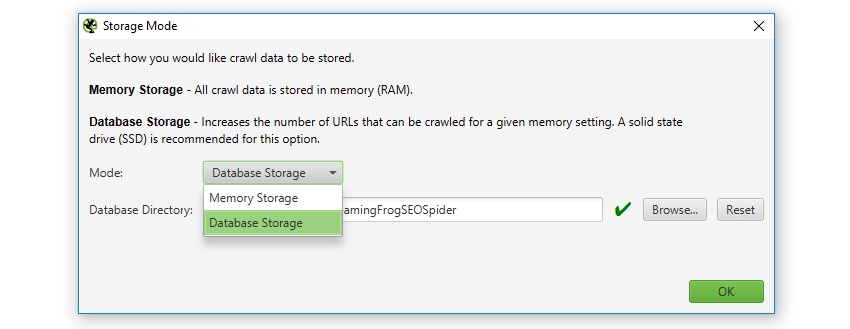
users without an SSD, or are low on disk area and have lots of RAM, may additionally prefer to proceed to crawl in memory storage mode. whereas other users with SSDs could have a alternative to simply crawl using 'database storage mode' via default. The configurable storage makes it possible for clients to dictate their journey, as each storage modes have benefits and disadvantages, counting on computing device requisites and state of affairs.
Please see our ebook on the way to crawl very huge web sites for more detail on both storage modes.
The saved crawl layout (.seospider info) are the same in each storage modes, so that you are capable of delivery a crawl in RAM, retailer, and resume the crawl at scale while saving to disk (and vice versa).
2) In-App reminiscence Allocationfirst off, apologies for making every person manually edit a .ini file to raise reminiscence allocation for the final 8-years. You're now able to set reminiscence allocation within the software itself, which is a bit greater person-friendly. This will also be set below 'Configuration > system > reminiscence'. The SEO Spider may also communicate your actual memory put in on the gadget, and help you configure it rapidly.
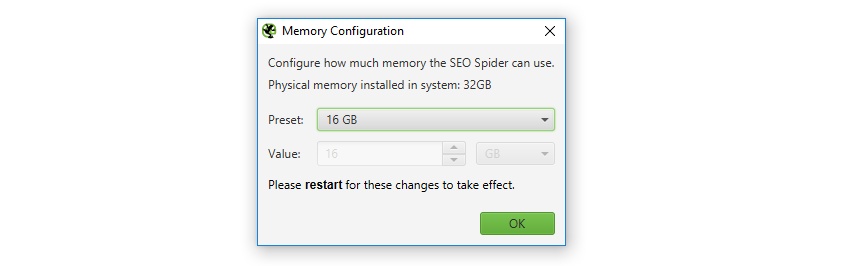
expanding memory allocation will permit the search engine marketing Spider to crawl greater URLs, specially when in RAM storage mode, but also when storing to database. The memory acts like a cache when saving to disk, which enables the search engine optimization Spider to perform sooner movements and crawl more URLs.
three) keep & View HTML & Rendered HTMLthat you may now choose to shop each the raw HTML and rendered HTML to inspect the DOM (when in JavaScript rendering mode) and view them within the decrease window 'view supply' tab.
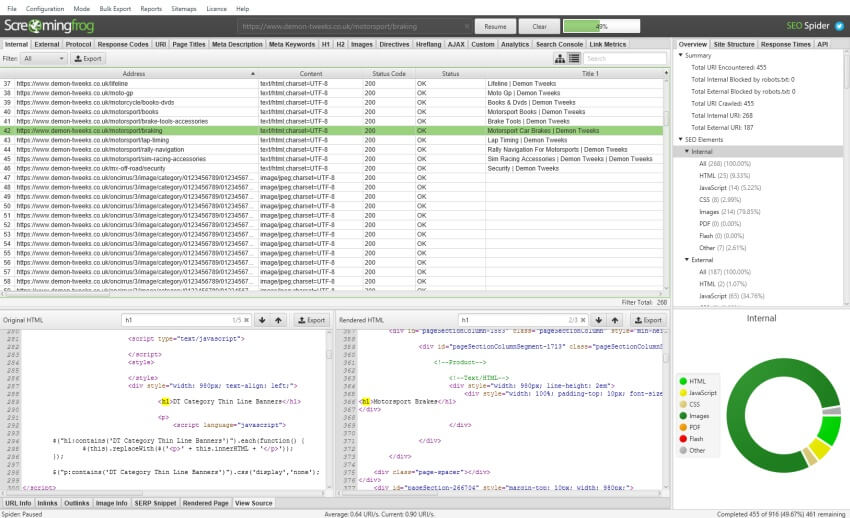
here's super positive for a variety of situations, corresponding to debugging the changes between what's seen in a browser and in the search engine marketing Spider (you shouldn't should use WireShark anymore), or just when analysing how JavaScript has been rendered, and even if certain elements are within the code.
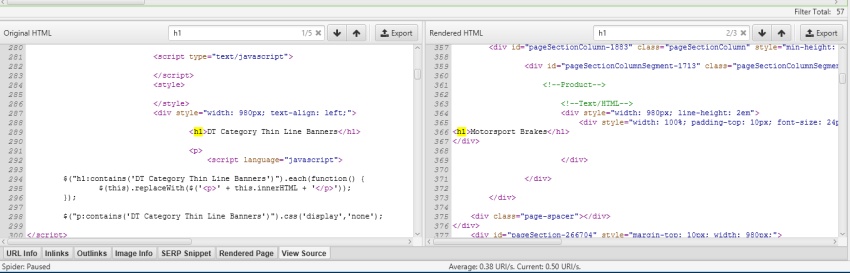
which you can view the usual HTML and rendered HTML on the same time, to examine the adjustments, which will also be principally valuable when points are dynamically constructed by using JavaScript.
you could flip this characteristic on under 'Configuration > Spider > superior' and ticking the acceptable 'store HTML' & 'keep Rendered HTML' options, and additionally export all of the HTML code through the use of the 'Bulk Export > All web page supply' accurate-stage menu.
we've some further points planned here, to aid users establish the variations between the static and rendered HTML.
4) customized HTTP HeadersThe search engine marketing Spider already offered the potential to configure consumer-agent and settle for-Language headers, but now users are in a position to fully customize the HTTP header request.
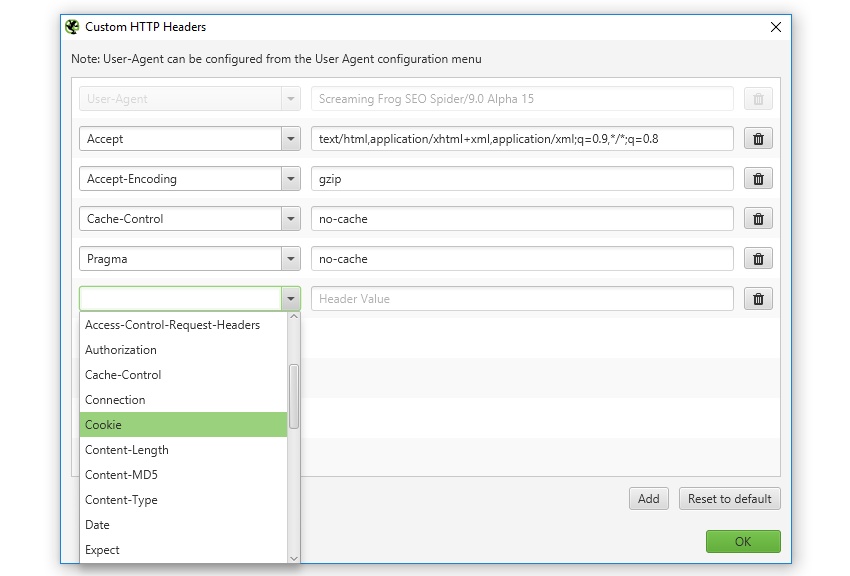
This skill you're in a position to set anything from the accept-encoding, cookie, referer, or simply supplying any entertaining header identify. This can also be advantageous when simulating using cookies, cache handle common sense, trying out behaviour of a referer, or other troubleshooting.
5) XML Sitemap advancementsYou're now able to create XML Sitemaps with any response code, in place of simply 200 'ok' fame pages. This allows flexibility to rapidly create sitemaps for quite a lot of situations, corresponding to for pages that don't yet exist, that 301 to new URLs and also you want to drive Google to re-crawl, or are a 404/410 and also you want to remove at once from the index.
when you've got hreflang on the site set-up accurately, then which you could also select to include hreflang in the XML Sitemap.
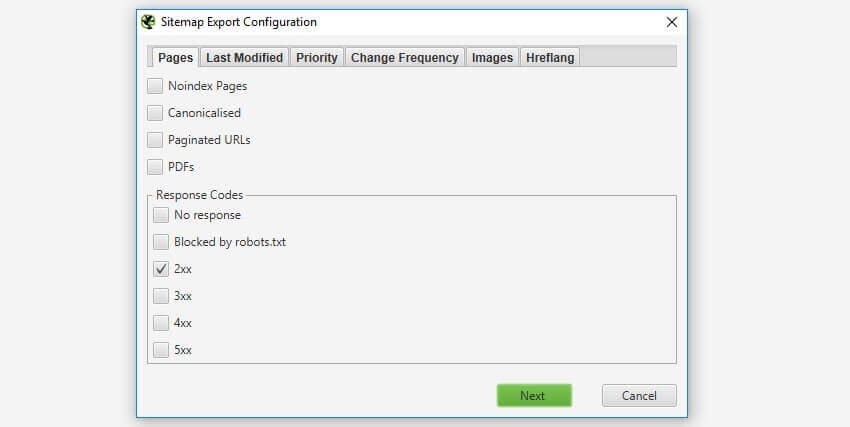
Please observe – The web optimization Spider can best create XML Sitemaps with hreflang if they are already current presently (as attributes or by way of the HTTP header). more to come back right here.
6) Granular Search functionalityprior to now when you performed a search within the search engine optimisation Spider it could search across all columns, which wasn't configurable. The search engine optimization Spider will now search towards just the tackle (URL) column by means of default, and you're in a position to choose which columns to run the regex search in opposition t.
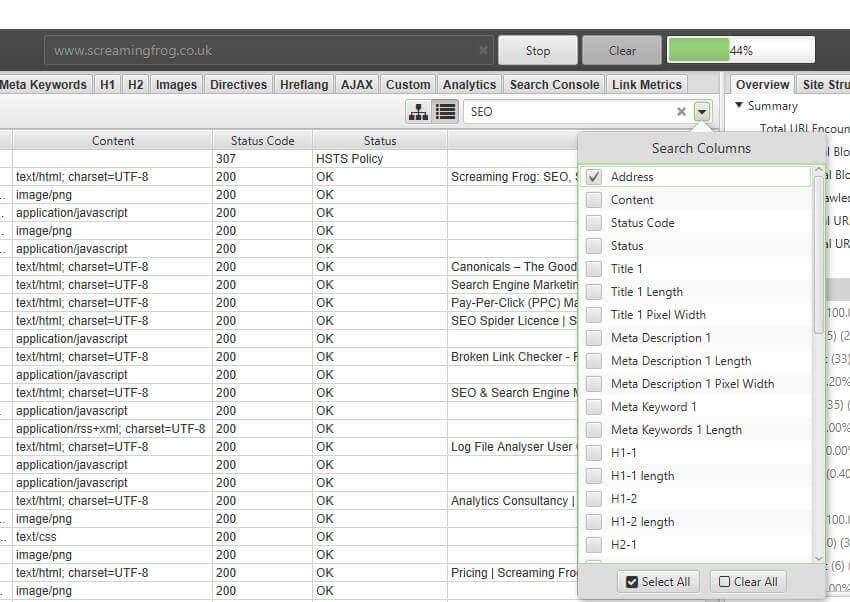
This definitely makes the quest functionality quicker, and extra beneficial.
7) up-to-date SERP Snippet EmulatorGoogle extended the common length of SERP snippets vastly in November closing year, where they jumped from around 156 characters to over 300. based mostly upon our research, the default max description length filters had been increased to 320 characters and 1,866 pixels on computer inside the web optimization Spider.
The lower window SERP snippet preview has also been up to date to reflect this trade, so that you can view how your web page might appear in Google.
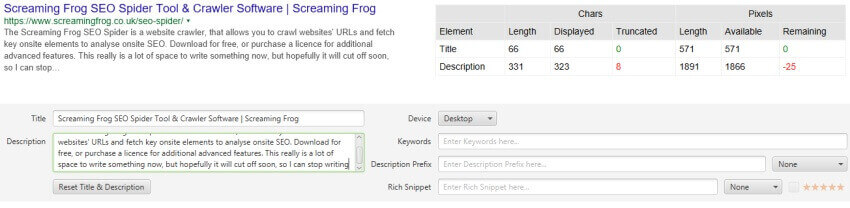
It's worth remembering that here is for computer. cellular search snippets also extended, but from our research, are rather just a little smaller – approx. 1,535px for descriptions, which is commonly below 230 characters. So, if loads of your site visitors and conversions are by way of cellular, you might also need to replace your max description preferences under 'Config > Spider > Preferences'. that you can switch 'device' class inside the SERP snippet emulator to view how these appear distinctive to computing device.
As outlined in the past, the SERP snippet emulator could nonetheless be every so often a be aware out in either course compared to what you see within the Google SERP due to exact pixel sizes and bounds. Google additionally every now and then reduce descriptions off much earlier (primarily for video), so please use simply as an approximate ebook.
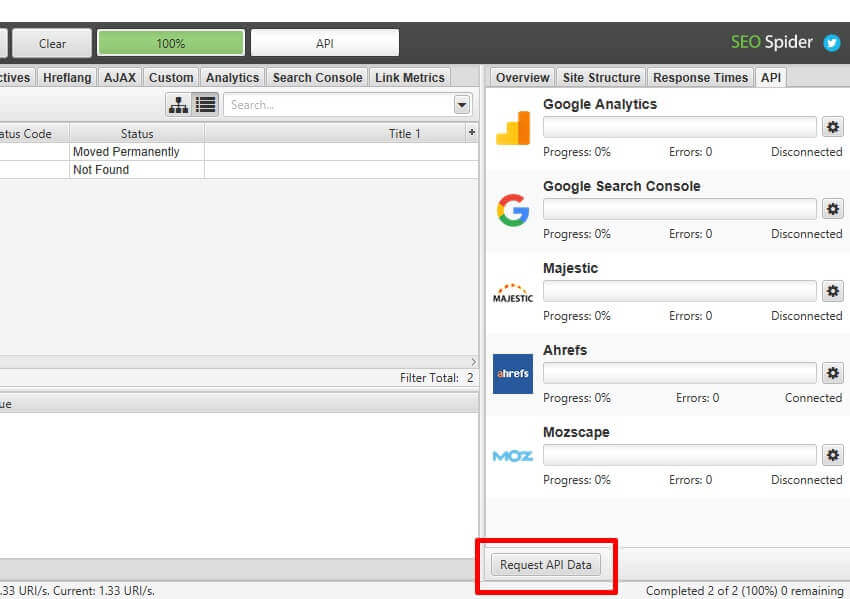
eight) post Crawl API Requestsfinally, if you neglect to connect to Google Analytics, Google Search Console, Majestic, Ahrefs or Moz after you've began a crawl, or understand on the very end of a crawl, that you can now connect to their API and 'request API statistics', with out re-crawling all the URLs.
version 9.0 also includes a couple of smaller updates and computer virus fixes, outlined under.
That's every thing for now. this is a huge release and one which we're happy with internally, as it's new floor for what's workable for a computer utility. It makes crawling at scale extra available for the search engine optimization community, and we hope you all like it.
As all the time, in case you adventure any complications with our latest replace, then do tell us by the use of assist and we are able to support and resolve any concerns.
We're now starting work on edition 10, where some long standing characteristic requests could be covered. because of everyone for all their patience, feedback, assistance and endured guide of Screaming Frog, it's really liked.
Now, please go and download version 9.0 of the Screaming Frog search engine optimization Spider and let us know your innovations.



0 comments: